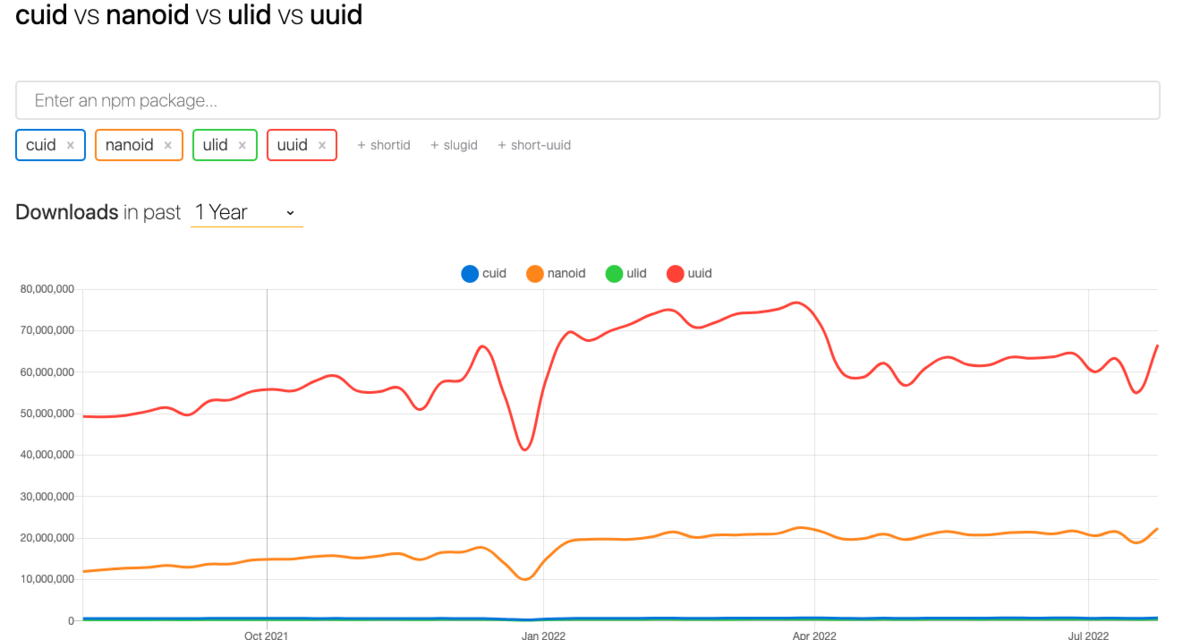
今回はバックエンドAPIでページネーションをどうやるかについての話なので、よくある無限スクロールUIのようなフロントエンド側の実装に関する話はしない。あくまでもAPI、もっと言えばRESTfulなAPIのリクエスト・レスポンスにおけるページネーションの話。
本気で深く考えるというよりざっくり検討したときの話です。
はじめに
REST APIを実装するにあたってリスト系のAPIを提供する場合に必須といっても過言ではないのがページネーション。大量のリソースをレスポンスする場合にそれらを一気に返してしまうことは応答速度、転送量、クライアントサイドでの扱いづらさなどなどに繋がるので必須と言える。
最近、新たなAPIを開発するにあたってページネーションをする必要があったこともあり、今回はこのページネーションをどうやって提供するか整理して改めて検討してみた。
前提
一応前提を書いたものの、言語やフレームワーク固有の話にはあまり踏み込まず汎用的な話だと思う。
なお、今回のようにNest.jsを使っている場合はそのものずばりなライブラリが用意されていたりする。
nestjs-paginate - npm
さらにTypeORMとの組み合わせならばこんなのもある。
nestjs-typeorm-paginate - npm
これらについては詳細も見ていないし、使ったこともないので今回は紹介するにとどめておく。
実装パターン
さて、まず最初に思いつく実装パターンをいくつかあげてみる。他にもあるかもしれないが多くはこれらのパターンに大別されるのではないか。知らないだけで他にもあるかもしれない。
パターンとして大まかにリクエストとレスポンスのそれぞれでこのように分けられる。
- LIMITとOFFSETを指定する方式
- ページ番号方式
- カーソル指定方式
そしてこれらをクエリパラメータとして表現するかリクエストボディとして表現するかに分かれる。ただし、基本的にはクエリパラメータで表現することのほうが多いと思われる。とはいえこれはそもそものGETリクエストをどう処理しているかによるだろう。例えばGETのクエリ条件が複雑だったりで最大長を超えるケースなど(ただし、RFC的にはURLの最大長は定義されていなくてブラウザなどの実装依存だったはず)はボディに含めるしかないはず。
LIMITとOFFSETの方式はあくまでも指定したオフセットから件数を制限して取得しているだけなのでページネーションというかは微妙なところではある。ただし、実装としては一番楽で、なぜならこれはそのままSQLに当てはめられるのだ。この方式の場合は基本的にリクエストされた値をそのままSQLのLIMITとOFFSETに渡すだけで基本的には成立する。
また、この場合は後述するレスポンスへのメタ情報の格納も必要ないだろう。
ページ番号方式はわかりやすいし事前に用意もしやすいが、新しいデータが追加されたり削除されたりしたときに取得結果が重複してしまうといった意味では一貫性がないとも言える。
極端な例だがページサイズが10件だとした場合に、2ページ目にアクセスした後に先頭に10件追加されてしまうと次のページである3ページにアクセスしても先にアクセスした2ページ目の内容と同じ内容が表示されてしまう。とはいえこれってユーザにとってちょっと不便なだけでもあるので、これがどこまで大きな問題として扱うかはシステムやデータの特性次第とも言える。
実装の観点でいうと基本的にはLIMIT/OFFSET方式に加えてページ数の計算が増える。なお、総件数についてはどこで保持するかという問題がある。件数が多いと毎回計算なんてやってられない。別途それ用にRedisとか使ってもいいけどひとまず最小限の労力でやるならキーとなるIDごとの総件数だけを保持するKey-Valueなテーブルを用意して更新時にカウントアップするっていう方法もなくはない。
カーソル方式は次のページの先頭レコードを何らかのトークンやカーソルといったもので保持したり指定する方式。ここでのカーソルの値は対象オブジェクトをシリアライズしたものだったりなんでもいい。
この方式だと先に挙げた一貫性の問題は比較的大丈夫と言える。なぜならあくまでも指定したカーソル以降のデータを取得するので対象のデータ内にデータが追加された場合を除けば重複の問題はおきないだろう。時間が経った後にアクセスしても内容が変わることも無い。
だがカーソル方式だとUIでよくある何ページ目を表示するっていうオペレーションは実現できない。また特性上前のページに戻るというオペレーションを実現することも難しいだろう。一方で件数がめちゃめちゃ多いときとかにはいい気がしていて、無限スクロールとの相性はいいと思われる。
実装的にはこの中では一番手間がかかる。といっても大した手間ではないが。
基本的な流れは以下のような感じ。
- カーソルの値のデコード
- デコードした値を起点にクエリ実行。このときページサイズの+1件を取得する
- +1件で取得したレコードのID等をカーソルの値としてエンコード
- 3の値とともにレスポンス
2でやる+1件は次のカーソルを取得するためだけど、結果セットの最後のレコードで代用することもできると思う。
ちなみにこの書籍ではREST APIの実装パターンが数多く紹介されているのだが、ここではページネーションの方式としてカーソル方式を紹介している。
そして避けるべきパターンとして上で紹介したLIMITとOFFSETを用いるパターンを挙げている。
その理由としては『実装の詳細がAPIに表出してしまうこと』をあげていた。あとは将来的にデータストアが分散DBなどの複雑なものになった場合にオフセットの開始点をどう見つけるかといった点で計算コストなどの課題が出てくると。
そして先ほどの一貫性の問題も挙げられている。
レスポンス
ページネーションでは次のページの情報などのメタ情報が必要をクライアントに伝える必要があり、これをレスポンスのどこかに格納する必要がある。とはいえ、これはLinkヘッダかレスポンスボディの2パターンくらいだと思う。別のレスポンスヘッダに格納することもできるが。
Linkヘッダを使うパターンは本来レスポンスとして返す情報とメタ情報が分かれているので、個人的には綺麗だと思っている。
例えばGET /users?page=2のレスポンスに以下のようなヘッダをつけて返す。
Link: <https://example.com/users?page=1>; rel="previous",
<https://example.com/users?page=3>; rel="next",
<https://example.com/users?page=10>; rel="last",
一方で利用するフレームワークやSDKにこのあたりの機能が提供されていないとサーバーサイド、クライアントサイドともに処理が多少面倒な可能性がある。サーバーサイドはヘッダ情報を組み立てる必要があるし、クライアントサイドはレスポンスからLinkヘッダを取り出し、パラメータを取り回す必要がある。
レスポンスボディに含めるパターンは深く考えなくていいので簡単と言える。1つのレスポンスボディ内に本来返すべき情報とは別にメタ情報を格納するプロパティを用意して一緒に返すだけだし、クライアントサイドは普通にレスポンスボディをparseすればいいだけだ。多くの場合はJSON形式だろうからどの言語でも簡単に目的の値を探索できる。
先の例と同じく例えばGET /users?page=2にリクエストするとレスポンスとしてこんなものを返す。
{
"_link": {
"previous": "https://example.com/users?page=1",
"next": "https://example.com/users?page=3",
"last": "https://example.com/users?page=10"
},
"users": [
{
"id": xxx,
"name": xxx
},
{
"id": xxx,
"name": xxx
}
]
}
なお、Linkヘッダの場合もレスポンスボディの場合もパラメータ名ないしはプロパティ名については各社様々だが、Linkヘッダそのものはこういったものだ。
Link - HTTP | MDN
各サービスの実装
次に著名な各Webサービスがこのあたりをどういった形で提供しているのか参考に見てみる。令和時代の新実装が見つかることを期待している。
REST API 内での改ページ位置の自動修正の使用 - GitHub Docs
大正義GitHubのAPIではどうなっているか。
GitHubでは呼び出すAPIによって返す値のデフォルト件数が異なるとのこと。ページネーションに関する情報は、API 呼び出しの Link ヘッダーで提供され、次のページと最後のページへのリンクがそれぞれ以下のようにLinkヘッダに含まれている。
Link: <https://api.github.com/search/code?q=addClass+user%3Amozilla&page=2>; rel="next",
<https://api.github.com/search/code?q=addClass+user%3Amozilla&page=34>; rel="last"
クライアントは次のページをリクエストするときはrel="next"となっているリンクをそのまま指定すればいいし、総ページ数はrel="last"のリンクからわかる。ただし、 URLを推測したり自分で構築するのはダメってことだが最初のリクエスト以降はジャンプするのもOKみたいだ。例えば14ページ目にジャンプしたときはLinkヘッダの中身は以下のようになる。
Link: <https://api.github.com/search/code?q=addClass+user%3Amozilla&page=15>; rel="next",
<https://api.github.com/search/code?q=addClass+user%3Amozilla&page=34>; rel="last",
<https://api.github.com/search/code?q=addClass+user%3Amozilla&page=1>; rel="first",
<https://api.github.com/search/code?q=addClass+user%3Amozilla&page=13>; rel="prev"
rel="next"とrel="last"はそれぞれ先ほどと同じく次のページと最後のページ(総ページ数)だが、新たにrel="first"と'rel="prev"'というのが追加されている。これらはそれぞれ1ページ目と前のページってこと。ヘッダからの値の取り出しとかっていう処理はあるものの見た目にはとてもわかりやすい。
Pagination | Docs | Twitter Developer Platform
Twitterの場合はレスポンスに含まれるnext_tokenとprevious_tokenおよびリクエストのクエリパラメータのpagenation_tokenでコントロールする。初回のリクエストのレスポンスに含まれるnext_tokenの値をpagenation_tokenというクエリパラメータで指定してリクエストする。2ページ目以降のレスポンスにはprevious_tokenも含まれる。この値は単なるページ番号ではなく数桁の文字列となっている。
1ページあたりの件数はmax_resultsで指定できるようだが総件数はわからないっぽい。また、ダイレクトに特定ページにジャンプすることも難しいと思われる。
Google Custom Search
Method: cse.list | Custom Search JSON API | Google Developers
これはGoogleの検索結果をAPIで取得するのに使うもの。
さらっとドキュメント見ただけでは正直なところよくわからなかったのだが、どうやらクエリパラメータのnumとstartでコントロールするみたいだ。numで1回のリクエストに含まれる件数を指定する。startは何件目から取得するかを指定するパラメータみたいで、例えば1回あたり10件だと2ページ目、つまり11件目以降を取得する際はnum=10&start=11と指定することになるらしい。
そしてレスポンスはさらに複雑だった。レスポンスのJSONにはrequest/previous/nextが含まれていてそれぞれにtotalResultsやstartIndexといった値が含まれている。
Introduction · Product Advertising API 5.0
Amazonの商品検索とかのAPIであるがここではSearchItems APIを参考にしてみる。
SearchItems · Product Advertising API 5.0
シンプルにリクエストのパラメータとしてItemPageとItemCountを指定する。ただしAmazonの場合はクエリパラメータではなくリクエストボディにJSON形式でセットする模様。そしてレスポンスにはTotalResultCountに総件数が含まれるのでそれを使って自分で計算してリクエストするみたい。
こういう形式って初回のリクエストをしてようやく総件数がわかるんだとすると検索結果下部に各ページへのリンクを張るようなUIは構築しにくいような気もするがどうなんだろうか。
Atlassianのconfluence
Pagination in the REST API
クエリパラメータのlimitで件数を指定し、startでオフセットを指定するパターン。そしてページの情報はレスポンスボディに含まれている。
"_links": {
"base": "http://localhost:8080/confluence",
"context": "",
"next": "/rest/api/space/ds/content/page?limit=5&start=10",
"prev": "/rest/api/space/ds/content/page?limit=5&start=0",
"self": "http://localhost:8080/confluence/rest/api/space/ds/content/page"
},
格納しているURLとしてはLinkヘッダの場合と同様だけど、nextとかprevとかがレスポンスのJSONのプロパティとして表現されているので取り回しは楽そう。
Strapi
Sort & Pagination for REST API - Strapi Developer Docs
strapiも基本的にはページ番号指定方式でメタ情報はレスポンスに含める形式。ただし、クエリパラメータとして指定するページ番号の指定の仕方はちょっと独特だった。
GET /api/articles?pagination[page]=1&pagination[pageSize]=10
レスポンスに含まれるメタ情報はトータルの件数にページサイズ、現在のページ、そして総ページ数。
Stripe
Stripe API reference – Pagination – curl
Stripeはカーソル方式。1回のリクエストで取得するオブジェクトの数をlimitというクエリパラメータで指定する。そして取得したオブジェクトの最後のオブジェクトのIDをstarting_afterというクエリパラメータで指定するとそのオブジェクト以降のオブジェクトをリストで取得できる。
こういう方式なのでレスポンスには取得したオブジェクト以降にもデータがあるかを示すhas_moreというフラグ以外に特にメタデータは含まれていない。
Pagination | REST API Handbook | WordPress Developer Resources
WordPressはページ番号指定方式。だけどOFFSETっぽいこともできる。pageというパラメータで直接指定することもできるし、そのスタート位置をoffsetというパラメータで指定することもできる。例えばページサイズがデフォルトの10件の状態でoffset=5と指定した場合に最初のページは6件目から15件目までのものがレスポンスされる。
そしてメタ情報はレスポンスのヘッダに含まれるのだけどLinkヘッダではなくX-WP-TotalとX-WP-TotalPagesという2つのヘッダを用いる。次のページに関する情報は特段レスポンスしない模様。
最後にこれはサービスではないんだけどPythonのフレームワークであるDjangoがページネーションをサポートしていてドキュメントにもまとまっている。
Pagination - Django REST framework
Djangoの場合、紹介したパターンすべてをサポートしている。つまりリクエスト方式としてはLIMIT/OFFSET方式、ページ番号方式、カーソル方式のいずれもサポートしているし、メタ情報の返し方としてもボディに入れる方式とLinkヘッダに入れる方式のどちらもサポートしているのだ。加えてContent-Rangeというヘッダでも返せるっぽいのだけど詳細は見つけられなかった。
では我々はどうするか
ここまで思いつくパターンと有名企業各社やプロダクトの実装を眺めてきた。紹介はしていないが実は他にもいくつか見たのだが傾向としては以下のような感じだ。
- リクエストはページ番号指定方式が多い
- メタ情報はレスポンスボディに含める
- 特に目新しいパターンはなかった
というわけで検討した結果、今回は以下にすることにした。なお、今回はキャッシュのしやすさや実装におけるパフォーマンス面での比較検討はできていない。
- リクエストはページ番号指定方式
- メタ情報はLinkヘッダに含める
まず、リクエストをページ番号指定方式にした理由はシンプルに今回作るシステムのUIで特定のページにジャンプさせるようなものを用意するからだ。
こういうやつ。

また、LIMIT/OFFSET方式はDBの実装が露出しているようで嫌だしカーソル方式だとこのようなUIは難しいのではないかと思った。また、一貫性の問題については許容することとした。
メタ情報をLinkヘッダに格納するかレスポンスボディに入れるかはどちらでもいいと思う。が、今回はLinkヘッダに入れる方式を採用した。理由としてはそれほど深いものがないのが正直なところだけど、一応思ったのはレスポンスボディには本来欲しい情報の結果だけにしたいなというのが大きい。
あとはLinkヘッダ方式の悩みどころとして値の取り回しだったのでクライアント目線だとレスポンスボディに入れたほうがいいかなと思っていたんだけど、これについてはこんなライブラリ見つけたのでそこについてもまあいっかなと。
www.npmjs.com
最終的には両方サポートするかもしれない。そんなに手間でもないので。
まとめ
- 令和時代の〜という大げさなタイトルにしたものの、特に新しい方式やトレンドがあるわけではない
- とはいえLinkヘッダ方式は10年以上前にはあまり見かけなかった気もする
- 自分の実装はLinkヘッダとページ番号指定方式にした
- GeoJsonも扱う必要があるがこれについてはどうすればいいかさっぱりわからなかった
というわけで『令和時代のページネーションを考える・実装編』に続きます。実装し始めたら考えが変わるかもしれない。


 トルエンフリー ジャコビアン 370ml")
 スチールウール#0000 200g TSW0000-200")


 旧リョービ サンダ MS-30B 93×228mm 636432A 【握りやすくて操作性がよい扱いやすい入門機】 ペーパー寸法93×228mm パッド寸法91×185mm 回転数11000min-1 軽量1.3Kg")

 1.5Ahバッテリ2本・充電器付ケース付 MTD001DSX")
 コードレス電動ドライバー IXO6 ダークグリーン 無段変速 正逆転切替 LEDライト (ビット10本 充電器・ケース付) 締付工具 ドリルドライバー")






![AWSコンテナ設計・構築[本格]入門](https://m.media-amazon.com/images/I/51m2BetgRZL._SL500_.jpg "AWSコンテナ設計・構築[本格]入門")


![LeanとDevOpsの科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する impress top gearシリーズ](https://m.media-amazon.com/images/I/51TuqLnPBCL._SL500_.jpg "LeanとDevOpsの科学[Accelerate] テクノロジーの戦略的活用が組織変革を加速する impress top gearシリーズ")
![体系的に学ぶ 安全なWebアプリケーションの作り方 第2版[固定版] 脆弱性が生まれる原理と対策の実践](https://m.media-amazon.com/images/I/41WBMf7zcML._SL500_.jpg "体系的に学ぶ 安全なWebアプリケーションの作り方 第2版[固定版] 脆弱性が生まれる原理と対策の実践")




")


")
















")